The Tech Sales Newsletter #56: Is observability still worth it for tech sales?
Sales anon,
The focus of this newsletter is the tech sales opportunity in cloud infrastructure software. At a high level, that means the cloud hyperscalers, data platforms, AI, cybersecurity and observability.
While all of these are mission critical, some of them can command higher investments from customers compared to the others. In recent years observability exploded into the public attention, particularly with the high growth performance of Datadog, which was rewarded heavily by investors who drove the stock to one of the highest revenue/valuation ratios in the industry.
This week we will explore the growth thesis for observability compared to the other parts of the cloud infrastructure software stack.
So what exactly is this so-called-observability?

Source: Claude generated diagram
Let's define first what we are trying to achieve, who achieves it and what is the software stack to support that vision.
What are we trying to do: Develop and/or implement applications that help achieve the business goals of the company. If you are H&M and you want to launch a new web-store, you would have your developers and IT operations coordinate, work on the project and be responsible for keeping it running post launch.
Who achieves it: The technical teams involved (developers and IT staff of variable roles) would adopt a set of practices and tools (DevOps) that help them achieve better outcomes. Some of those aspects would be related to working jointly rather than as separate entities, utilise automation and tools to reduce the manual work required to launch, collaborate on identifying and managing the right infrastructure, troubleshoot and solve outages or performance issues post-launch.
What is the software stack to achieve this: Now here we already introduce the first challenge, since the right question is more related to what are we trying to achieve specifically and what would be the best tool for the job.
Let's look at how Datadog presents it's observability vision:
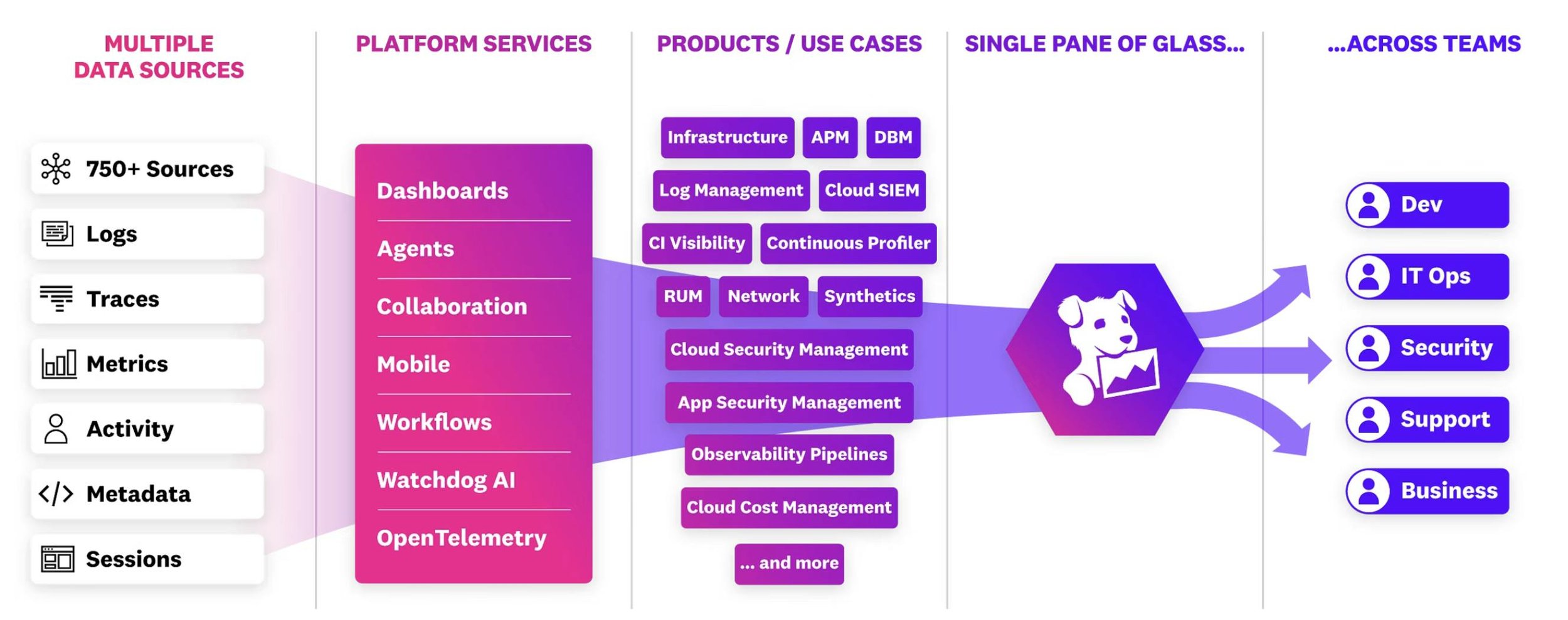
Source: Datadog's Observability platform overview
From the point of view of the pure-play observability vendors (Datadog, Dynatrace, Grafana), observability is a continuation of those DevOps practices in a technical solution that allows to have a broader view of the state of the systems involved and the inputs/outputs that lead to changes in the behaviour of the system.
The rough idea is that you might see that the H&M webshop that we mentioned is having difficulties being accessed in Chicago, but that doesn't mean that you need to now restart all the servers that keep the service running in Chicago. There could a number of reasons for the outage, which could be internal or external and an advanced platform would be able to collect all the necessary information (logs, traces and metrics), help you analyse it and conduct root cause analysis to solve the problem.
What is the core business value of observability? It should allow for an organisation to run it's most important applications effectively and efficiently.
The two words here are chosen on purpose, since they illustrate the fundamental gap between what DevOps practitioners expect and want vs what the vendors offer.
Effectively: Should I do a significant investment on an Observability platform in order to ensure my applications keeps running at all times? Well, yes and no. Remember how every couple of months half of the internet goes down because AWS North Virginia has an outage? In theory, this should never happen if those platforms could keep everything running perfectly. But that's now how things work in real life, because while automation is valuable on the efficiency end, the reality is that there are way too many different things that can go wrong in any given time.
There is a patch that broke something (Crowdstrike, cough cough). There is a physical issue with a datacenter (server fried). There is misconfiguration by a developer. There is spike in demand that the system is not being able to handle, etc, etc.
That's why these platforms focus on visualisation and the concept of a "single pane of glass". Ideally, the teams making sure that things are working will be able to have access to real-time analytics (typically in the form of dashboards) and alerts that give them the ability to investigate and solve outages quickly.
Fundamentally, there is a critical human element here required to solve the problems, rather than the system preventing all issues, at all times. If there is a human element required, then the obvious question is what is the balance between people capital and technical systems needed to achieve the outcome I want?
Efficiently: There are many practitioners who find observability to be a marketing term, rather than a reflection of their day-to-day. Implementing and running logging, monitoring and alerting already solves the technical capabilities needed to achieve the outcomes they need.
By constantly expanding and adding more volume of data that's being ingested and analysed, the vendors are able to increase their ARR from these accounts, but the customers often end up paying a lot more, for no or very incremental real life improvement of outcomes. Some argue, that by focusing on single, complex platforms, DevOps teams are often presented a simplified view of their complex systems and are lured into believing that spending more will really correlate with better outcomes.
Shot, chaser

Source: DHH's X
I've previously written about the history of SaaS and how we progressed from open-source -> perpetual licenses -> cloud. Recently one of the well respected SMB software companies (37signals) in the industry had taken a bit of a crusade to promote a return to perpetual licenses and pulling away from the cloud hyperscaler ecosystem.
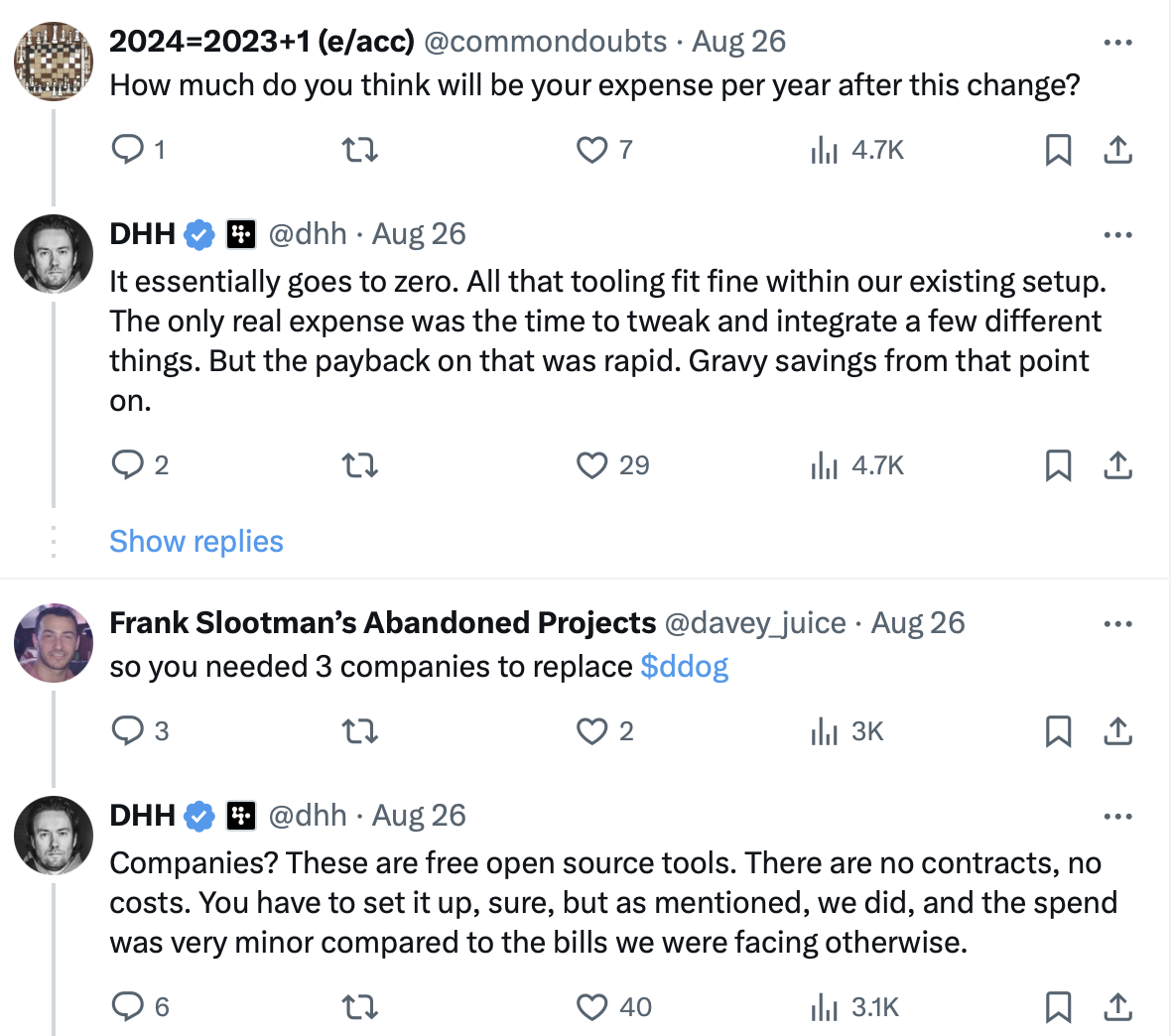
Source: DHH's X
Their next step is clearly taking on the software stack behind DevOps by canceling their Datadog subscription.
The situation is the perfect illustration of the problem of finding the right balance on effectiveness and efficiency when it comes to observability. 37signals is a company that offers two primary products - Basecamp (CRM/project planner for SMBs) and Hey (email client, both regular and business users). Their whole business depends on making sure these applications are running and are secure. They generate tens of millions in profit with a very small team (under 100 employees). So logically speaking, spending 83k ARR on their primary observability platform should be the most obvious and easy to justify expense.
Due to the way they run their business and the products they offer, their use case is rather simplistic from an observability perspective. Their primary use case would be logging and visualisations, together with app monitoring which they were able to combine in this stack. The response from the wider DevOps community:

Source: DHH's X
Now there are several dynamics here.
DevOps is by definition a very technical community. That often means that a) they like tinkering with stuff b) they don't see the point of paying for something they think that should be free.
Open-source products can fulfil their technical requirements in almost all situations
They hate the sales reps and how unpredictable the costs are.
Now, the tech sales point of view in response to this is also important:
Technical users typically lack a deeper understanding of how mission critical different systems are and struggle to visualise the ROI of different approaches.
Technical users would often waste time on less-productive priorities because of personal preferences/technical comfort zone.
Most technical users are not open to the feedback that in most cases, they are running subpar internal services that are not achieving the right outcomes, which is frustrating business users.
Open-source might be free for you to use, but it's not free to develop. The primary open-source stack components, Prometheus/Loki and ELK stack are both developed by tech companies (Grafana and Elastic) who depend on customers converting from open-source to their paid offerings. By starting from the view point that you should never pay for mission critical enterprise software, you basically set up the whole ecosystem for failure because these tools could never evolve into the more complex observability products that exist today. "But we also contribute to the software!" is a great concept that barely plays out in real life - the companies behind these products produce 99% of the relevant code.
The last part is very important. Just because they adopted a number of open-source tools, doesn't suddenly mean they are able too use them properly. And if they are using them properly, that doesn't mean that it's an efficient use of their time compared to the alternative.
For 37signals, a company with technical founders and very clear focus on the products that they use and understanding of the audience they serve, running an open-source observability stack might make sense. For most companies, that might not be the case. It's the job of a tech sales rep to have a point of view of what the right approach for their specific needs might be.
So what does that mean for pure-play observability vendors?
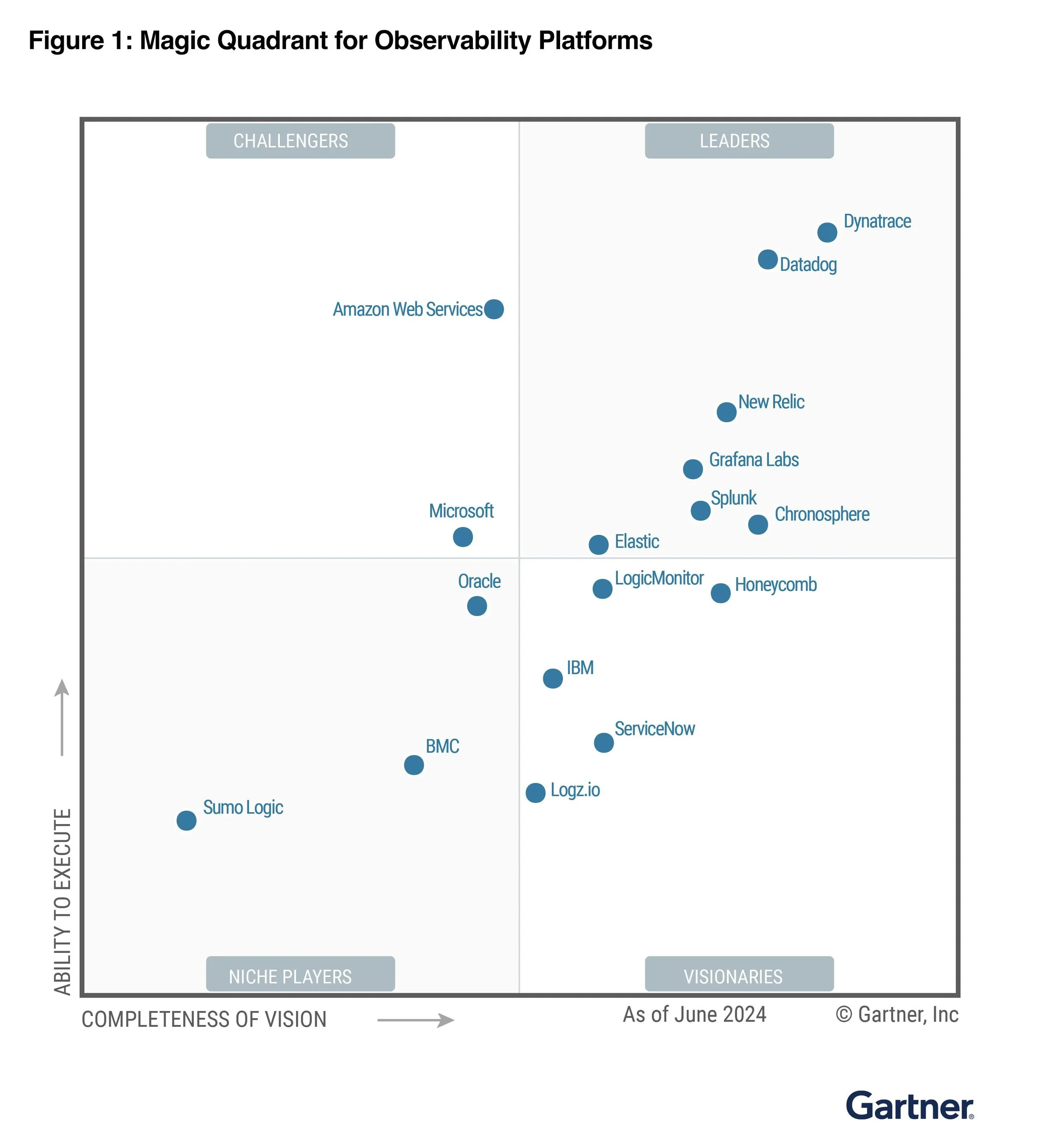
Source: Gartner Magic Quadrant for Observability 2024
The big question in this article is - where can I get paid and what would realistically the future of working for an observability vendor look like?
As we've outlined so far, there are a lot of viewpoints on whats necessary and what is not necessary in a tech stack to achieve the right outcome. Observability vendors experienced tremendous growth during the '20-22 period because suddenly companies really had to prioritise uptime as most of the things that mattered, moved into applications that had to be accessible at all times. Spending millions (with zero interest rates) on a mission critical tech stack made sense in that moment.
Once the workload optimisation drive started, the demand started to stagnate significantly, with customers looking to reduce their bills.

Source: RepVue
This is not impressive, to say the least. Growth for Dynatrace and Datadog has been in the 20%-27% range in the last year, a clear step down from top tier cybersecurity or data platform vendors. More importantly, attainment has been poor across the board. I'm sparing you from digging into other "leaders" in the Magic Quadrant like Chronosphere with their 16% attainment.

Source: RepVue review for Dynatrace

Source: RepVue review for Grafana

Source: RepVue review for Datadog
These reviews are a good reflection of what the situation on the ground is - great products for the right use case, however there is clearly a significant gap between what your average customer wants and needs vs what the company is pushing. The reps often lack that nuance and vision, so they get stuck with low attainment unless they luck out with an account that has the right fit. The companies are a positive environment to work at for the most part, so reps are generally willing to leave positive reviews even if they struggle with their day-to-day or earn less than what they would've liked.
Ok TDD, message received. But this is just temporary, things will turn around, right?
What happens when there is a misalignment between what the biggest and best companies offer vs what most of the market wants? New competition comes in.
Fuelled by strong open-source communities, VCs looking for the next big story in observability and some technical developments, there are more new approaches and products than ever before in this space.
There is a new open-source tech stack that has emerged recently that fundamentally challenges the current approach of "ingest what you can (logs, metrics, traces), from where you can (whatever you can afford)".

Source: Claude generated diagram
The components of it:
OpenTelemetry (OTel) + eBPF + Clickhouse: This is getting into the most technical aspects of deploying an advanced observability stack by in-house. I would recommend going trough this deep dive but at a high level, what we are looking at is collecting both application-level insights (OTel) together with system-level visibility (eBPF) in high performance database with smaller infra footprint.
There are a number of new vendors entering the space and building upon this stack, as well as large and sophisticated end users adopting it in-house because they have the technical knowledge.
The reason why this matters is because if the whole premise of getting paid in the future depends on winning the most valuable use cases with Datadog for example, then having an open-source stack that's more powerful and cheaper to run when competing for these use cases is bad news.
If then the viewpoint is that this development doesn't matter because the pure-play vendors should corner the less technical customers, we get into the other issue which is companies having shrinking observability budgets and willingness to struggle with multiple open-source components to reduce cost.

Source: DHH's X
3 years ago, this was probably a bad idea for a number of them. In the time of heavy adoption of LLMs and ML for coding and configuring technical systems, the potential outcomes and technical knowledge required are significantly different.
Conclusion
The bull case for growth for pure-observability companies is fundamentally tied to increasing the consumption (ARR) of an individual customer over time.
The value proposition for increasing ARR depends on ingesting more data and adopting more tools within the same platform.
There are significant trends in the industry right now that lead to customers re-evaluating whether a) they need more tools to achieve the same outcome b) whether ingesting data the way that it currently works or of this size has a sufficient proportional impact to justify the investment.
The history of the industry is also fundamentally tied to incumbents capturing high value workloads, then getting displaced on price for similar functionality/outcomes.
If this article was written in 2019, the closed-sourced vendors we would be talking about would be Splunk, AppDynamics and New Relic, with the ELK stack dominating the open-source adoption for logging. The reality is that the big growth of Datadog, Dynatrace and Grafana was driven by being cheaper displacements that over time were able to offer better platforms. While Datadog and Dynatrace have cemented themselves as the primary pure-play vendors of 2024, their market share is being challenged by a number of players predominantly on similar capabilities offered at a lower cost.
It's important to understand that history never fully repeats itself, but it does rhyme. The now-considered-legacy observability vendors had their big growth period because they offered enterprise-level solutions, while DevOps was still in its infancy and open-source tools were used in very simplistic workflows.
The big growth by the current observability leaders was driven partly by functionality, partly by costs, and partly by observability being seen as an essential part of the tech stack on board level.
That means that there are no "easy wins" going forward. LLMs and the big wave of compute usage for AI will bring new workloads to the industry, but it's a double edged sword - many of those workloads will go to open-source tools (implemented with help of both closed-source and open-source LLMs). The big winner from this will be as usual, the bottom of the stack (the cloud hyperscalers). AWS is a major player in logging due to literally hosting a fork of the ELK stack under the brand OpenSearch.
As such, my personal prediction is that pure-play observability vendors will start consolidating, but their growth trajectories are unlikely to continue as aggressively as before. Most of the business will also be displacement of competition for existing workloads rather than benefiting from type of growth that came in '20-22 from new data being generated and ingested.
Hiring will need to remain stagnant or significant restructuring and layoffs are needed to right-size for what the reality on the ground will look like.

Source: RepVue's QA for Datadog
Getting a 12k SPIFF for turning a loss for the company in the first year on a new logo is not what long term success looks like.
In this overview I'm not even touching on the impact that data platforms with strong observability play have on the market share distribution or the recent pivot of large cybersecurity vendors to compete for SIEM workloads (security analytics has been a grey area that's often serviced by and stored in observability tools).
The quota attainment is low for reasons that go deeper than just "market downturn". There are better opportunities in tech sales for the foreseeable future.