The Tech Sales Newsletter #73: 2024 in AI and the path forward
This is the final "Tech Sales" newsletter for the year. I envisioned 2024 as a "building" year, both in terms of the industry and my own personal projects.
As with every "building" year, the important thing was setting up the foundations that we can build upon going forward. It was not about easy wins or victory laps but grinding through the work that needs to be done.
Quota attainment in the industry didn't improve significantly. Headcount remained mostly stagnant, with big layoffs being replaced by PIPs and silent departures. Most of the year was spent in anticipation of the US election, as wars raged on in several parts of the world and markets fluctuated.
It was 2 years ago when ChatGPT launched. It triggered an avalanche of activity, as most industry insiders realized that we were about to take a generational leap in how we utilize computing power. Most of 2023 was about feeling out the potential.
2024 was about building towards a direction.
2025 will be about winning big and widening the gap. Rather than repeating the key events of the last twelve months, I'll focus on several key areas you should pay attention to.
The key takeaway
For tech sales: OpenAI's latest model is benchmarking at what we would consider AGI level for all practical purposes (i.e., it can replace an average worker). At launch, the cost per task is too high for mass adoption, but this is likely to change significantly within 12 to 24 months. If you are not currently working for a company well-positioned to perform in the new paradigm (i.e., a cloud infrastructure software vendor), you should seriously reconsider your options.
For investors: The majority of value always accrues at the bottom of the stack. The foundation of the AI stack consists of OpenAI, Anthropic, Meta, xAI, Databricks, NVIDIA, AWS, Azure, and GCP. The beta will reside at the top of the stack, with preferred data platforms, observability, and cybersecurity vendors that integrate within the hyperscaler ecosystem. This thesis required "conviction" in 2024; in 2025, it will become "obvious."
The o3 elephant in the room

Source: OpenAI
On December 20th, OpenAI hosted a 22-minute YouTube video with Sam Altman and Mark Chen (SVP of Research). As part of their "12 Days of Shipmas" series of product updates, they revealed the benchmarks for o3, their next frontier model targeting a launch in late January.
It's important to understand how deliberately understated the whole event was. Sam and Mark sat at a table in a small office with decorations in the background, a laptop, and two guests who joined them awkwardly over the course of the discussion.
This would make sense for a minor product reveal, similar to the updates they made over the previous 11 days. This, however, was no ordinary moment.
They kicked off by sharing several benchmarks that would set the tone. The new model showed a significant jump in performance in math, coding problems, and PhD-level science. So what?
The stage was set for Greg Kamradt to come on. He was there to present how o3 benchmarked in the context of Arc-AGI, a specific set of problems designed to test whether the model could essentially learn and grow when introduced to new problems.
To make deliberate progress towards more intelligent and human-like systems, we need to be following an appropriate feedback signal. We need to define and evaluate intelligence.
These definitions and evaluations turn into benchmarks used to measure progress toward systems that can think and invent alongside us.
The consensus definition of AGI, "a system that can automate the majority of economically valuable work," while a useful goal, is an incorrect measure of intelligence.
Measuring task-specific skill is not a good proxy for intelligence.
Skill is heavily influenced by prior knowledge and experience. Unlimited priors or unlimited training data allows developers to "buy" levels of skill for a system. This masks a system's own generalization power.
Intelligence lies in broad or general-purpose abilities; it is marked by skill-acquisition and generalization, rather than skill itself.
Here's a better definition for AGI:
AGI is a system that can efficiently acquire new skills outside of its training data.
More formally:
The intelligence of a system is a measure of its skill-acquisition efficiency over a scope of tasks, with respect to priors, experience, and generalization difficulty.
- François Chollet, "On the Measure of Intelligence"
This means that a system is able to adapt to new problems it has not seen before and that its creators (developers) did not anticipate.
ARC-AGI is the only AI benchmark that measures our progress towards general intelligence.
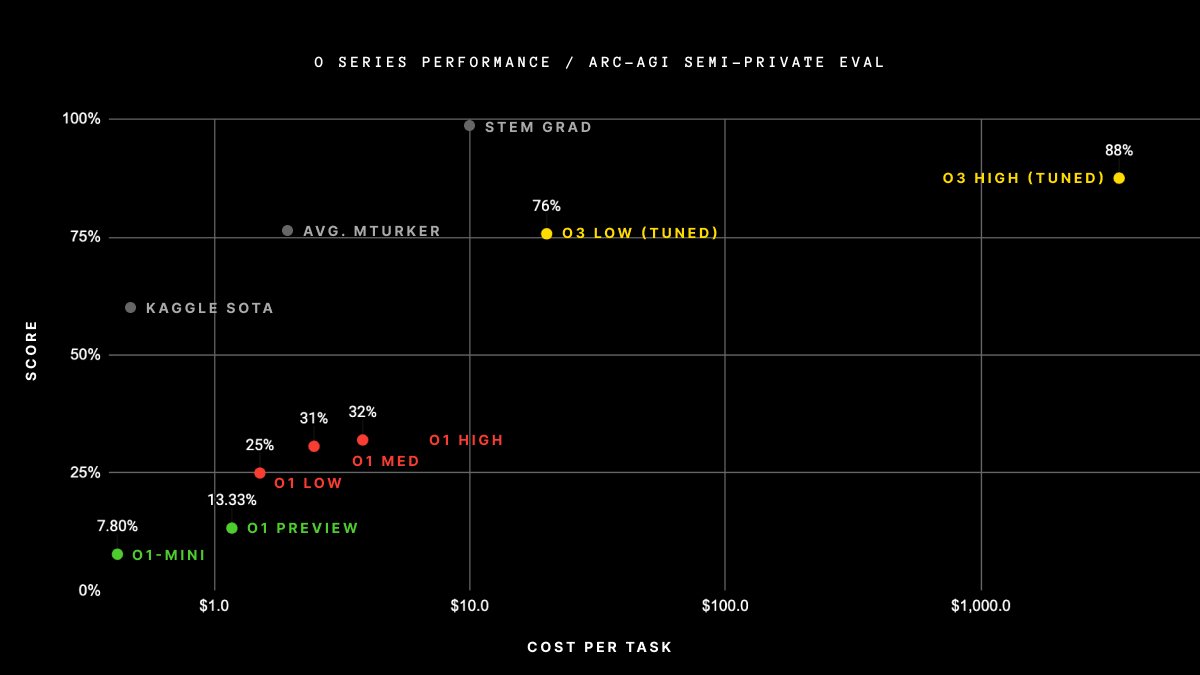
Source: Arc Prize
o3 is the first model that has successfully tested above 85%, which the benchmark considers to be human-capability level. This was done by utilizing a significant amount of compute, so the actual cost of achieving the result was also much higher than what we've seen from o1 Pro (which is currently priced at a $200 monthly subscription for a limited set of uses per month).

Source: OpenAI
To put this into perspective, o3 is benchmarking at a 175 spot for Codeforces' ELO score competition, which would put it in the 0.1% performance level of all tests taken in the last 6 months.
For all intents and purposes, we just achieved AGI. The attempt to downplay this as much as possible was successful - media coverage was non-existent. There are some obvious questions to be asked here, such as why announce something that OpenAI is intentionally misrepresenting? The two likely scenarios are related to either the commercial agreement with Microsoft or the desire to avoid government intervention. Technically, under the commercial terms between OpenAI and Microsoft, they need to reach $100 billion in profit for "AGI" to be considered achieved (Microsoft gets a cut for everything before that figure). The government intervention angle should not be understated either.

Source: @pmarca on X
So what does this really mean? Well, there are a couple of critical angles here from a tech sales perspective:
If o3 performs at the level indicated by these benchmarks, companies will be able to not only automate parts of workflows but potentially fully outsource the low-end and middle-of-the-bell-curve employees who support those workflows.
If o3 underperforms in January, over a long enough timeline (12-24 months), the odds of a model achieving the goal above are now "very likely."
The cost curve of utilizing the model is likely to be on par with or higher than the cost of the replaced employees. This is extremely likely to decrease by a significant margin over the next 12-24 months.
As usual, launching the model is just the beginning of developers and innovators building on top of it. The additional applications that will launch based on this new capability will likely outperform many existing products and market leaders in specific niches.
The most limiting factor might be access to compute to run these models. The early adopters will derive exponentially higher value as they carve out key resources from their laggard competitors.
More importantly, “text-to-application” is now much more likely to become a reality, along with all the implications this has for tech sales. As per my ending of that article:
Historically, tech sales teams have been the lever used to pull companies to a market leader positions.
As the software landscape changes, I think that we will see a lot less opportunities for "anybody" to get into tech sales. In bigger companies this is becoming a question of profitability - those companies need to either generate a lot more revenue with the same resources or scale down their operations to a realistic level for their product.
In smaller companies, the whole concept of scaling is becoming an intense discussion. If startups have been traditionally a great entry point for complete newbies because they were comfortable with the risks involved, in the future we might start seeing only very experienced and talented individuals get the opportunity, driving a mostly automated GTM motion. The profile of such individuals is likely to be T-shaped:
Big brother is watching us
As already hinted in the previous section, as we continue to accelerate towards "recognized" AGI, there will be significant pressure on and from governments. This is too big of a topic to be just left to tech companies to play with. Even if the impact over the next 10 years is limited to knowledge workers alone, the implications for local economies can be significant. Let's say that this disrupts the consulting business so fundamentally that 25% of the current workforce is no longer needed.
"It's just consultants, TDD, who cares?"
Well, those consultants are regular taxpayers in their local economies. They raise children, they pay mortgages, they consume products, and they often have limited job transferability unless taking a significant pay cut. They also tend to vote and would be willing to lobby to keep their jobs.
Yonadav Shavit from OpenAI published on X his rather extended personal view on the implications of policy regarding o3 and AGI:
Now that everyone knows about o3, and imminent AGI is considered plausible, I’d like to walk through some of the AI policy implications I see.
These are my own takes and in no way reflective of my employer. They might be wrong! I know smart people who disagree. They don’t require you to share my timelines, and are intentionally unrelated to the previous AI-safety culture wars.
Observation 1: Everyone will probably have ASI. The scale of resources required for everything we’ve seen just isn’t that high compared to projected compute production in the latter part of the 2020s. The idea that AGI will be permanently centralized to one company or country is unrealistic. It may well be that the *best* ASI is owned by one or a few parties, but betting on permanent tech denial of extremely powerful capabilities is no longer a serious basis for national security. This is, potentially, a great thing for avoiding centralization of power. Of course, it does mean that we no longer get to wish away the need to contend with AI-powered adversaries. As far as weaponization by militaries goes, we are going to need to rapidly find a world of checks and balances (perhaps similar to MAD for nuclear and cyber), while rapidly deploying resilience technologies to protect against misuse by nonstate actors (e.g. AI-cyber-patching campaigns, bioweapon wastewater surveillance).
Observation 2: The corporate tax rate will soon be the most important tax rate. If the economy is dominated by AI agent labor, taxing those agents (via the companies they’re registered to) is the best way human states will have to fund themselves, and to build the surpluses for UBIs, militaries, etc. This is a pretty enormous change from the status quo, and will raise the stakes of this year’s US tax reform package.
Observation 3: AIs should not own assets. “Humans remaining in control” is a technical challenge, but it’s also a legal challenge. IANAL, but it seems to me that a lot will depend on courts’ decision on whether fully-autonomous corporations can be full legal persons (and thus enable agents to acquire money and power with no human in control), or whether humans must be in control of all legitimate legal/economic entities (e.g. by legally requiring a human Board of Directors). Thankfully, the latter is currently the default, but I expect increasing attempts to enable sole AI control (e.g. via jurisdiction-shopping or shell corporations). Which legal stance we choose may make the difference between AI-only corporations gradually outcompeting and wresting control of the economy and society from humans, vs. remaining subordinate to human ends, at least so long as the rule of law can be enforced. This is closely related to the question of whether AI agents are legally allowed to purchase cloud compute on their own behalf, which is the mechanism by which an autonomous entity would perpetuate itself. This is also how you’d probably arrest the operation of law-breaking AI worms, which brings us to…
Observation 4: Laws Around Compute. In the slightly longer term, the thing that will matter for asserting power over the economy and society will be physical control of data centers, just as physical control of capital cities has been key since at least the French Revolution. Whoever controls the datacenter controls what type of inference they allow to get done, and thus sets the laws on AI. Notably, this makes civil liberties associated with compute much higher stakes. One important solution is individual physical ownership of compute, but I think given economies of scale we will probably also need to have certain protections w.r.t. individual use of centralized compute (e.g. the 4th amendment, a right to access, a right to privacy, etc). Otherwise, the risk that the state compels obedience from everyone by seizing the datacenters becomes too great. At the same time, it seems plausible to me that it will not be possible to run a society without being able to enforce penalties on rogue/criminal AI agents. The only intervention that can limit these agents’ continued propagation in the real world is denial of compute (there’s no such thing as putting an AI agent in jail). This implies some need for verification of compute purchaser identity by data center operators, which is already a thing that happens in many cases. Just to ensure no misunderstanding: chip export controls are just as important in a world of test-time compute scaling to AGI - they will determine how much AI each country can use. As an aside, earlier in my career, I investigated “verifying training compute use” under the hypothesis that pretraining scaling would be the dominant AI paradigm, and that an international treaty based off the NPT could help arrest a military AI training arms race. I no longer believe that idea is technically or politically viable, for a number of reasons. That said, I do think there’s a bunch of promising technical ideas for using secure computing to improve the privacy-transparency tradeoff for certain AI policies (like using TPMs for to verify an AI agent is who they say they are).
Observation 5: Technical alignment of AGI is the ballgame. With it, AI agents will pursue our goals and look out for our interests even as more and more of the economy begins to operate outside direct human oversight. Without it, it is plausible that we fail to notice as the agents we deploy slip unintended functionalities (backdoors, self-reboot scripts, messages to other agents) into our computer systems, undermine our mechanisms for noticing them and thus realizing we should turn them off, and gradually compromise and manipulate more and more of our operations and communication infrastructure, with the worst case scenario becoming more dangerous each year. Maybe AGI alignment is pretty easy. Maybe it’s hard. Either way, the more seriously we take it, the more secure we’ll be. There is no real question that many parties will race to build AGI, but there is a very real question about whether we race to “secure, trustworthy, reliable AGI that won’t burn us” or just race to “AGI that seems like it will probably do what we ask and we didn’t have time to check so let’s YOLO.” Which race we get is up to market demand, political attention, internet vibes, academic and third party research focus, and most of all the care exercised by AI lab employees. I know a lot of lab employees, and the majority are serious, thoughtful people under a tremendous number of competing pressures. This will require all of us, internal and external, to push against the basest competitive incentives and set a very high bar. On an individual level, we each have an incentive to not fuck this up. I believe in our ability to not fuck this up. It is totally within our power to not fuck this up. So, let’s not fuck this up.
Why are insiders discussing tax reform and laws about whether "corporations are people, too" should apply to AI?
Why is Marc Andreessen appearing on podcasts to discuss his concerns about the US administration's intentions to control companies in this space?
Why is Eric Schmidt debating model safety, as a policy advisor, for US and EU AI-related legislation for over a year?
Do you understand, or do I need to spell it out for you?
The boring and inevitable enterprise adoption
While the Go-to-Market teams across multiple key companies in the cloud infrastructure software space were grinding hard and converting PoCs into large deployments, Wall Street was too busy trying to short the hyperscalers because "GPUs are too much of a capital-intensive investment."
In the meantime, Azure reached $10B ARR in inference revenue. This is a critical milestone because it's not driven by the hardware provided to OpenAI to train models (that's considered an outside investment from an accounting standpoint). More importantly, the foundation of this inference business was built before it became clear that runtime computing would drive significant model performance gains. For those struggling to understand what that means, let's take the Arc-AGI description:
What's different about o3 compared to older models?
Why does o3 score so much higher than o1? And why did o1 score so much higher than GPT-4o in the first place? I think this series of results provides invaluable data points for the ongoing pursuit of AGI.
My mental model for LLMs is that they work as a repository of vector programs. When prompted, they will fetch the program that your prompt maps to and "execute" it on the input at hand. LLMs are a way to store and operationalize millions of useful mini-programs via passive exposure to human-generated content.
This "memorize, fetch, apply" paradigm can achieve arbitrary levels of skills at arbitrary tasks given appropriate training data, but it cannot adapt to novelty or pick up new skills on the fly (which is to say that there is no fluid intelligence at play here.) This has been exemplified by the low performance of LLMs on ARC-AGI, the only benchmark specifically designed to measure adaptability to novelty – GPT-3 scored 0, GPT-4 scored near 0, GPT-4o got to 5%. Scaling up these models to the limits of what's possible wasn't getting ARC-AGI numbers anywhere near what basic brute enumeration could achieve years ago (up to 50%).
To adapt to novelty, you need two things. First, you need knowledge – a set of reusable functions or programs to draw upon. LLMs have more than enough of that. Second, you need the ability to recombine these functions into a brand new program when facing a new task – a program that models the task at hand. Program synthesis. LLMs have long lacked this feature. The o series of models fixes that.
For now, we can only speculate about the exact specifics of how o3 works. But o3's core mechanism appears to be natural language program search and execution within token space – at test time, the model searches over the space of possible Chains of Thought (CoTs) describing the steps required to solve the task, in a fashion perhaps not too dissimilar to AlphaZero-style Monte-Carlo tree search. In the case of o3, the search is presumably guided by some kind of evaluator model. To note, Demis Hassabis hinted back in a June 2023 interview that DeepMind had been researching this very idea – this line of work has been a long time coming.
So while single-generation LLMs struggle with novelty, o3 overcomes this by generating and executing its own programs, where the program itself (the CoT) becomes the artifact of knowledge recombination. Although this is not the only viable approach to test-time knowledge recombination (you could also do test-time training, or search in latent space), it represents the current state-of-the-art as per these new ARC-AGI numbers.
Effectively, o3 represents a form of deep learning-guided program search. The model does test-time search over a space of "programs" (in this case, natural language programs – the space of CoTs that describe the steps to solve the task at hand), guided by a deep learning prior (the base LLM). The reason why solving a single ARC-AGI task can end up taking up tens of millions of tokens and cost thousands of dollars is because this search process has to explore an enormous number of paths through program space – including backtracking.
So if we translate this into tech sales speak:
o3 breaks down the problem
o3 burns tokens to review all relevant information it knows about the problem
o3 tests combinations repeatedly until it finds an answer it considers "high quality"
This workflow is often referred to as Chain of Thought, but there seems to be more going on under the hood. The optimization will likely need to come from becoming more efficient in going through the full CoT process only for the most likely scenarios for any given problem, but I'll leave speculation (and discovery) to the many researchers working on these problems.
As I said in the beginning, this is too expensive at launch to become a standard workflow for "average" roles. Instead, we will likely see it utilized for more complex problems where there isn't sufficient human capacity to service the actual demand (let's say in a very niche line of chemistry). Until the cost drops (which could be a matter of months, not years), Enterprise will keep optimizing for efficiency and jobs to be done by utilizing agentic workflows and open-source models.
This is where we again see politics, corporate interests and technical breakthroughs intermingle:

Source: @deepseek_ai on X
DeepSeek is a Chinese company that just launched their latest open-source model and claims an exceptional price-to-performance ratio. More importantly, they claim this was achieved with very minimal training (partly due to heavy restrictions on compute availability imposed by the US government on Chinese companies). The estimated training cost was around $6M.
Now, where things start to get complex is the question of how much of this is true?
Source: @mathemagic1an on X
While both DeepSeek and Qwen are well-regarded models in the open-source community, there are significant reservations among US and EU companies about deploying these LLMs in mission-critical applications without fully understanding what the models might do when operating with system privileges in an agentic workflow.
In addition, there is the obvious question: "If they are violating ToS and stealing datasets for an open-source model, what is going on behind closed doors for the models that are not being released to the public?"
Due to this asymmetric compliance and security risk, Western companies are much more likely to continue investing in closed-source and open-source models from OpenAI, Anthropic, Meta, xAI, Databricks, NVIDIA, AWS, Azure, and GCP. As 95%+ of all inference revenue flows through these organizations, the ultimate moat becomes reality - tech companies that are too big to fail. The current H-1B visa debate exemplifies the dynamics behind the scenes - key players want to ensure nothing prevents them from bringing in the industry's best talent. Over time, independent researchers will mostly remain so due to ideological reasons - the opportunity to work on the hardest problems, with the most computing power and to become wealthy from it, will be solely concentrated in the companies above.
Let's go back to the practical realities of Enterprise adoption as of today.
LinkedIn recently published a detailed overview of their work during the last 2 years on the GenAI functionality for InMail writing suggestions within their recruiter-oriented product line.

Source: LinkedIn Engineering Blog
EON-8B is a fork of Llama 3.1 8B model focused on domain knowledge available to LinkedIn internally. From a cost-to-run perspective, one interesting highlight is how they progressed from 152 A100s to just 2 currently in production. Even GPT-4o wasn't as efficient as this configuration.
We're also talking about LinkedIn - the actual cost to operate these machines is limited to the bare metal + day-to-day operational upkeep; they likely aren't paying the full price this would cost to run on Azure as a regular workload. They still persisted in optimizing this, and the results speak for themselves.
"But TDD, if everybody heavily optimizes their implementations, how do we make money?"
My personal view is that the inference business is only suitable for the three hyperscalers who operate at a scale where cost reduction in one area simply results in spend in another. If you're not working for AWS, Azure, or GCP, then your next best opportunity is in the supporting ecosystem of cloud infrastructure software tools that support these applications (i.e., data platforms, observability, cybersecurity).
The goal would be to get customers to adopt and scale the right workflow for their needs. Agents is a likely model that would fit many use cases. Here is how Anthropic describes the thought process behind deploying agents:
"Agent" can be defined in several ways. Some customers define agents as fully autonomous systems that operate independently over extended periods, using various tools to accomplish complex tasks. Others use the term to describe more prescriptive implementations that follow predefined workflows. At Anthropic, we categorize all these variations as agentic systems, but draw an important architectural distinction between workflows and agents:
Workflows are systems where LLMs and tools are orchestrated through predefined code paths.
Agents, on the other hand, are systems where LLMs dynamically direct their own processes and tool usage, maintaining control over how they accomplish tasks.
Agents are emerging in production as LLMs mature in key capabilities—understanding complex inputs, engaging in reasoning and planning, using tools reliably, and recovering from errors. Agents begin their work with either a command from, or interactive discussion with, the human user. Once the task is clear, agents plan and operate independently, potentially returning to the human for further information or judgement. During execution, it's crucial for the agents to gain “ground truth” from the environment at each step (such as tool call results or code execution) to assess its progress. Agents can then pause for human feedback at checkpoints or when encountering blockers. The task often terminates upon completion, but it’s also common to include stopping conditions (such as a maximum number of iterations) to maintain control.
Agents can handle sophisticated tasks, but their implementation is often straightforward. They are typically just LLMs using tools based on environmental feedback in a loop. It is therefore crucial to design toolsets and their documentation clearly and thoughtfully.
When to use agents: Agents can be used for open-ended problems where it’s difficult or impossible to predict the required number of steps, and where you can’t hardcode a fixed path. The LLM will potentially operate for many turns, and you must have some level of trust in its decision-making. Agents' autonomy makes them ideal for scaling tasks in trusted environments.
The autonomous nature of agents means higher costs, and the potential for compounding errors. We recommend extensive testing in sandboxed environments, along with the appropriate guardrails.
Did you catch the point about higher costs when not limited to a well-tested "job to be done"? As with anything in tech sales, the difference between a successful customer implementation and an out-of-control budget lies in the fine details and choices made.
This is why most customers will opt to use agents provided by third parties rather than build their own.
To conclude - what should you focus on in 2025? Your goal is to find a company that either delivers great outcomes through agents or is a key part of the ecosystem behind building, running, and securing large implementations of LLM + Enterprise-grade Machine Learning. As frontier models continue to accelerate throughout the year, the definition of what agents can do will likely evolve dramatically.
Time in the market is significantly more important right now than timing the market. If your company isn't doing anything meaningful with AI and lacks the vision + technical capability to progress quickly in that direction, you're very exposed to disruption. The inverse, of course, also holds true.
If you're in the right place today, you will be the disruptor.